Full Unicode Search at 50× ICU Speed with AVX‑512

This article is about the ugliest, but potentially most useful piece of open-source software I’ve written this year. It’s messy, because UTF-8 is messy. The world’s most widely used text encoding standard was introduced in 1989. It now covers more than 1 million characters across the majority of used writing systems, so it’s not exactly […]
Pro-democracy HK tycoon Jimmy Lai convicted in national security trial

5 hours ago ShareSave Kelly Ng, Koey Leeand Danny Vincent,Hong Kong ShareSave Hong Kong pro-democracy campaigner and media tycoon Jimmy Lai has been found guilty of colluding with foreign forces under the city’s controversial national security law (NSL). The 78-year-old UK citizen, who has been in jail since December 2020, pleaded not guilty. He faces […]
$50 PlanetScale Metal Is GA for Postgres

By Richard Crowley | December 15, 2025 Today we’re making PlanetScale Metal for Postgres available in smaller sizes and at much lower price points, all the way down to the new M-10 for as little as $50 per month. We’ve lowered the floor from 16GiB of RAM with four sizes all the way to 1GiB […]
Thousands of U.S. farmers have Parkinson’s. They blame a deadly pesticide

Paul Friday remembers when his hand started flopping in the cold weather – the first sign nerve cells in his brain were dying. He was eventually diagnosed with Parkinson’s, a brain disease that gets worse over time. His limbs got stiffer. He struggled to walk. He couldn’t keep living on his family farm. Shortly afterward, […]
Carrier Landing in Top Gun for the NES
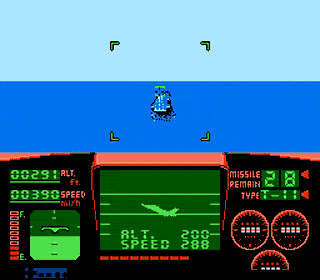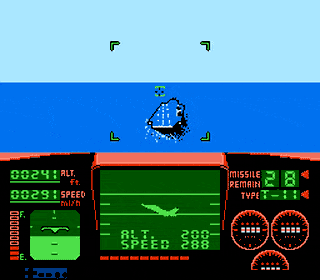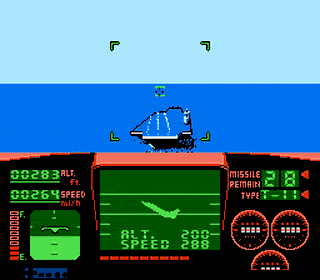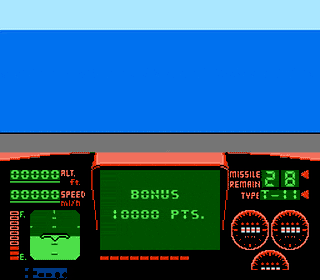
Best read with Danger Zone playing on loop Like most people, you’re probably an absolute expert at landing on the aircraft carrier in Top Gun for the NES. But if you’re in the silent minority that have not yet mastered this skill, you’re in luck: I’ve done a little reverse engineerining and figured out precisely […]
It seems that OpenAI is scraping [certificate transparency] logs
![it-seems-that-openai-is-scraping-[certificate-transparency]-logs](https://cdn-y.objects.dc-sto1.glesys.net/A1da965d3ac0f2e44c08f1ae072687d311/uploads/2025/12/537665-it-seems-that-openai-is-scraping-certificate-transparency-logs.jpg)
lol. I minted a new TLS cert and it seems that OpenAI is scraping CT logs for what I assume are things to scrape from, based on the near instant response from this: Dec 12 20:43:04 xxxx xxx[719]: l=debug m=”http request” pkg=http httpaccess= handler=(nomatch) method=get url=/robots.txt host=autoconfig.benjojo.uk duration=”162.176µs” statuscode=404 proto=http/2.0 remoteaddr=74.7.175.182:38242 tlsinfo=tls1.3 useragent=”Mozilla/5.0 (Macintosh; Intel […]
Avoid UUIDv4 Primary Keys

Introduction Over the last decade, when working on databases with UUID Version 4 as the primary key data type, these databases have usually have bad performance and excessive IO. UUID is a native data type in Postgres can be stored as binary data. Various versions are in the RFC. Version 4 has mostly random bits, […]
Fuzix on a Raspberry Pi Pico
Because your $5 microcontroller needed to run UNIX I recently discovered Fuzix while falling down a rabbit hole of reading about people’s hobby operating systems. Since I had some supported hardware (a Raspberry Pi Pico) laying around, I figured I’d try it out for myself. Fuzix is a descendant of UZI (with some other forks […]
Why proteins fold and how GPUs help us fold
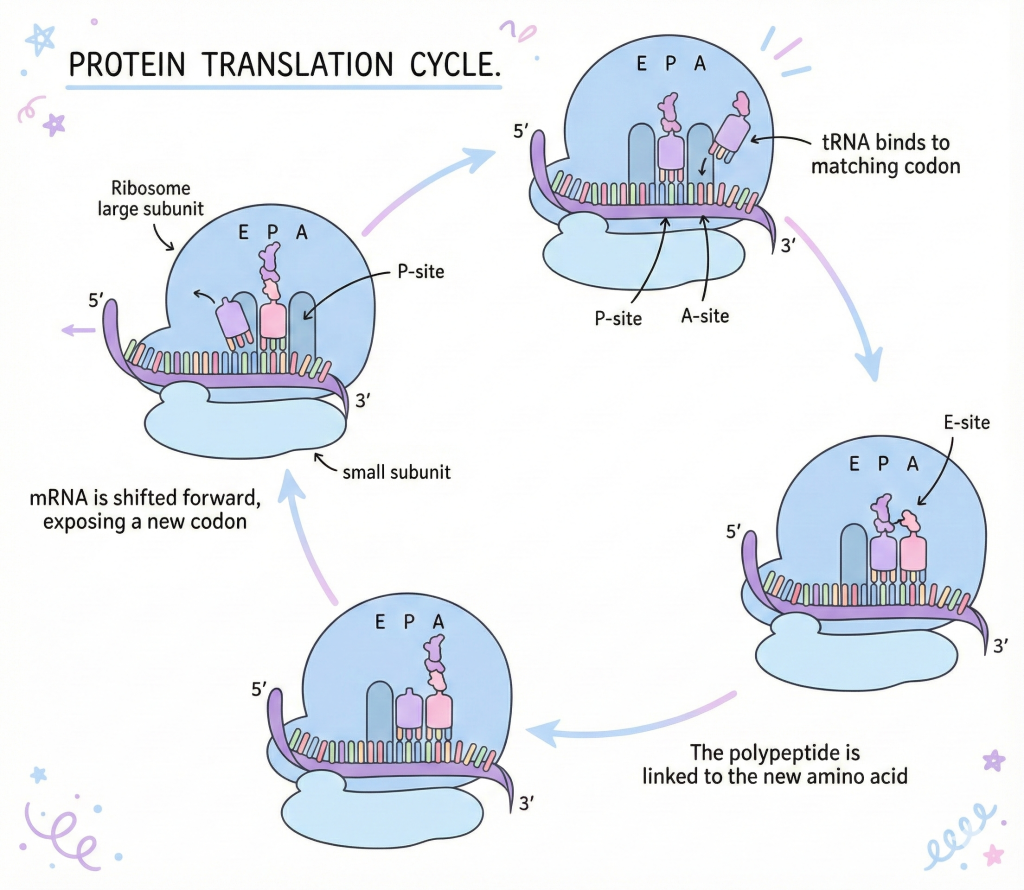
14 Dec, 2025 Before We Talk About AI, We Need to Talk About Why Proteins Are Ridiculously Complicated You know what’s wild? Right now, as you’re reading this, there are approximately 20,000 different types of proteins working inside your body. Not 20,000 total proteins, 20,000 TYPES. The actual number of protein molecules? Billions. Trillions if […]
Working quickly is more important than it seems (2015)
The obvious benefit to working quickly is that you’ll finish more stuff per unit time. But there’s more to it than that. If you work quickly, the cost of doing something new will seem lower in your mind. So you’ll be inclined to do more. The converse is true, too. If every time you write […]